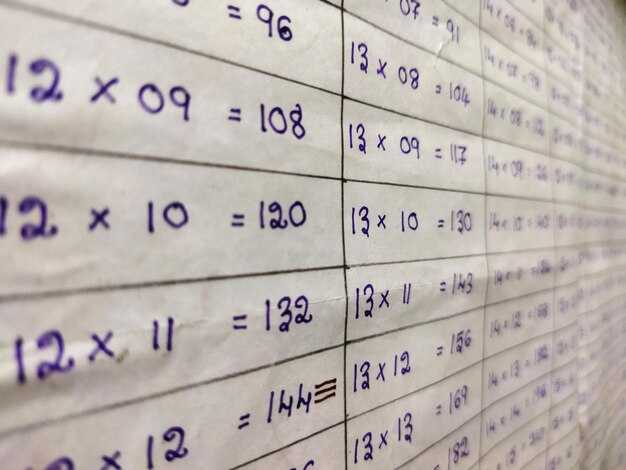
Для успешного распознавания рукописного текста на русском языке с помощью Python, рекомендуется использовать библиотеку Pytesseract, которая служит оберткой для инструмента Tesseract OCR. Начните с установки необходимых компонентов, включая сам Tesseract и соответствующие библиотеки Python. Это обеспечит стабильную работу вашего проекта.
Далее, подготовьте набор изображений рукописного текста. Чем лучше качество изображений, тем более точные результаты вы получите. Регулируйте размер, контрастность и четкость изображений перед обработкой. Рассмотрите возможность использования библиотеки OpenCV для предобработки изображений.
Когда изображения готовы, создайте простую программу на Python, чтобы интегрировать Pytesseract. Установите необходимые зависимости и начните с базового кода, который считывает текст с изображения. Не забывайте обрабатывать возможные ошибки, чтобы ваша программа оставалась стабильной.
Тестирование с разными примерами рукописного текста поможет вам улучшить точность распознавания. Доработайте вашу модель, экспериментируя с параметрами и алгоритмами, чтобы достичь наилучших результатов. Возможности Python в этом направлении практически безграничны, и вы сможете создать эффективное решение для ваших задач.
Подготовка данных для обучения модели распознавания
Соберите образцы рукописного текста на русском языке. Используйте различные шрифты и стилевые особенности. Разнообразие улучшает качество модели. Частота написания, наклон, размер буквы – все это учитывайте.
Создайте аннотированный набор данных. Каждой записи сопоставьте текстовую транскрипцию. Это основа для обучения. Аннотирование можно выполнять вручную, но для больших объемов данных используйте специальные инструменты или платформы, такие как LabelImg или VGG Image Annotator.
| Шаг | Описание |
|---|---|
| Сбор данных | Соберите около 10,000-20,000 примеров рукописного текста. |
| Аннотирование | Присвойте текстовую транскрипцию каждой записи. |
| Очистка данных | Удалите нечеткие или испорченные примеры. |
| Предобработка | Примените данные по стандартам, включая нормализацию и увеличение изображений. |
Аугментация данных также полезна. Создайте случайные вариации изображений, изменяя угол поворота, яркость или контрастность. Это поможет модели лучше обобщать информацию.
Разделите данные на обучающую, валидационную и тестовую выборки. Рекомендуйте использовать пропорцию 70/15/15. Это обеспечит корректную проверку производительности модели.
Использование формата изображения также играет роль. Наиболее распространены форматы PNG и JPEG. PNG лучше сохраняет качество изображений, но JPEG позволяет уменьшить объем памяти, что может быть важно для больших наборов данных.
Сбор и аннотирование рукописных данных
Чтобы собрать качественные рукописные данные, важно определить источники. Используйте собственные записи, анкеты и тестовые листы. Подготовьте шаблоны, которые легко заполнять. Убедитесь, что ваши образцы содержат разнообразные стили написания и шрифты.
Следующий шаг – аннотирование данных. Каждое изображение текста должно быть подписано, чтобы модель могла правильно обучаться. Для этого используйте инструменты, такие как LabelImg или VGG Image Annotator. Эти инструменты позволяют добавлять текстовые метки к изображениям ясным способом.
При аннотировании следите за точностью. Ошибки в маркировке могут исказить результаты обучения модели. Регулярно проверяйте и пересматривайте аннотации, чтобы избежать накопления ошибок.
Создайте небольшую команду, которая будет помогать в процессе аннотирования. Обсуждение возникших вопросов улучшит качество аннотаций. Онлайн-платформы, такие как Amazon Mechanical Turk, также могут помочь с увеличением объема работ.
Наконец, разделите собранные данные на обучающую и тестовую выборки. Это позволит проверить качество модели на независимых данных. Оптимальное соотношение – 80% для обучения и 20% для тестирования. Строгое соблюдение этих рекомендаций обеспечит надежность полученных результатов.
Предобработка изображений для улучшения качества распознавания
Для достижения высоких результатов в распознавании рукописного текста, важно тщательно подготовить изображение перед передачей его в систему распознавания. Начните с преобразования изображения в градации серого. Это поможет устранить цветовые помехи и сосредоточиться на черно-белых контрастах.
Следующим шагом – применение пороговой обработки. Метод Оцу позволяет выделить текст из фона, автоматически определяя optimal пороговое значение. Это создаст четкие границы между символами и фоном.
Шум на изображении может ухудшить качество распознавания. Используйте фильтр Гаусса для размытия изображения, что позволит сгладить мелкие детали и уменьшить шум. Это сохранит только основные контуры текста.
Важно также применить бинаризацию. Преобразуйте изображение в черно-белое, используя такие библиотеки, как OpenCV:
| Шаг | Описание |
|---|---|
| 1 | Загрузка изображения с помощью OpenCV. |
| 2 | Конвертация в градации серого. |
| 3 | Применение пороговой обработки с методом Оцу. |
| 4 | Фильтрация шума с помощью Гауссового размытия. |
| 5 | Бинаризация изображения. |
Ещё одним полезным приемом является увеличение контраста. Используйте линейную гистограмму или методы равномерного частотного распределения, чтобы улучшить четкость букв. Это позволит добиться более высокой точности распознавания.
При наличии деформаций текста, таких как наклон или искривление, примените коррекцию перспективы. Это поможет выровнять буквы и увеличить шансы на правильное распознавание.
Финальный этап предобработки – вырезание текста и уменьшение изображения до необходимого размера. Это способствует ускорению процесса распознавания и снижает нагрузки на модель.
Создание тренировочного и тестового наборов данных
Соберите рукописные образцы, которые будут служить основой для ваших наборов данных. Включите как можно больше различных стилей и шрифтов, чтобы добиться разнообразия.
Разделите собранные данные на две категории: тренировочную и тестовую. Рекомендуемый соотношение составляет 80% для тренировки и 20% для тестирования. Это обеспечит моделям достаточное количество данных для обучения, при этом оставив достаточно примеров для проверки их качественной работы.
Для создания тренировочного набора данных отсканируйте рукописные образцы и сохраните их в формате, удобном для обработки. Применяйте предобработку изображений: увеличьте контраст, уберите шумы, нормализуйте размеры. Храните данные в папках, организованным по классам символов или слов.
Для тестового набора данных отберите изображения, которые не использовались в тренировке. Обязательно проверяйте, чтобы тестовые образцы имели те же условия записи, например, качество и освещение, как и тренировочные. Это обеспечит сопоставимость.
Включите аннотации к изображениям, указывающие корректные тексты, чтобы облегчить процесс обучения модели. Используйте форматы JSON или CSV для хранения аннотаций, делая их легко доступными для дальнейшей обработки.
Используйте библиотеки, такие как Pandas, Numpy, и OpenCV, чтобы упростить работу с данными. Их функции позволят вам обрабатывать и анализировать изображения, а также готовить наборы данных для обучения моделей машинного обучения.
Не забывайте периодически обновлять наборы данных, добавляя новые образцы и исключая ненужные. Это поможет поддерживать высокую точность модели при работе с рукописным текстом.
Выбор и настройка моделей машинного обучения для русского текста
Рекомендуется начать с выбора подходящей архитектуры модели. Для обработки русского рукописного текста подойдут такие решения, как CRNN (Convolutional Recurrent Neural Network) или CNN (Convolutional Neural Network) в сочетании с RNN (Recurrent Neural Network). Эти модели хорошо справляются с задачами распознавания изображений и последовательностей.
После выбора модели важно настроить ее параметры:
- Гиперпараметры: Экспериментируйте с числом слоев, размером фильтров, размером пакета и коэффициентом обучения. Подбор этих параметров повлияет на качество распознавания.
- Количество эпох: Установите достаточное количество эпох для обучения. Обычно используется диапазон от 50 до 200, в зависимости от объема данных.
- Оптимизаторы: Применяйте Adam или SGD для адаптации градиентов, что может улучшить результаты.
Важно использовать обучающие данные, которые содержат разнообразные примеры рукописного текста. Хорошая практика — делить данные на обучающую, валидационную и тестовую выборки в соотношении 70/15/15.
Для русского текста покажите модели образцы букв, слов и предложений. Используйте такие наборы данных, как HANDWRITTEN DATASET или другие, содержащие рукописный текст на русском языке. После обучения тестируйте модель на новых данных, чтобы оценить ее работоспособность.
При необходимости обновите модель, добавив новые данные и повторно проведите обучение. Это может значительно улучшить точность распознавания и адаптацию к различным стилям письма.
Резюмируя, важно внимание к архитектуре, настройке гиперпараметров и качеству обучающих данных. Так вы получите модель, способную точно распознавать рукописный русский текст.
Обзор популярных библиотек для распознавания текста на Python
Рекомендуем обратить внимание на библиотеку Tesseract. Она поддерживает множество языков, включая русский. Установить её можно с помощью команды pip: pip install pytesseract. Эта библиотека отличается высокой точностью распознавания благодаря встроенной поддержке нейросетевых моделей.
Следующая на очереди — EasyOCR. Эта библиотека также поддерживает русский и множество других языков. Установка осуществляется через pip: pip install easyocr. EasyOCR использует современные нейросети, что делает её мощным инструментом для обработки изображений.
Не стоит забывать про OpenCV. Хотя она в первую очередь предназначена для компьютерного зрения, с её помощью можно также распознавать текст. Для этого необходимо совместить OpenCV с Tesseract, что открывает более широкий функционал в обработке изображений.
Библиотека Keras-OCR представляет собой ещё один интересный инструмент. Она использует глубокие нейросети для распознавания текста и хорошо справляется со сложными случаями, такими как рукописный или искажённый текст. Установка: pip install keras-ocr.
Если интересует работа с изображениями, способными отображать текст на различных языках, посмотрите на библиотеку PaddleOCR. Она предоставляет обширный набор инструментов для работы с текстом и поддерживает множество языков. Установка: pip install paddleocr.
Выбор библиотеки зависит от ваших конкретных задач. Если нужна простота и скорость, Tesseract будет отличным вариантом. Для более сложных случаев стоит рассмотреть EasyOCR или Keras-OCR. Каждая из библиотек имеет свои особенности, и вклад в работу с русским рукописным текстом значительно увеличится благодаря их особенностям.
Параметры настройки и их влияние на точность распознавания
Оптимизация параметров настройки значительно повышает точность распознавания русского рукописного текста. Сразу определите следующие ключевые аспекты:
- Шумоподавление: Удаление фона и излишних артефактов восстанавливает четкость изображения. Используйте алгоритмы обработки изображений, такие как фильтры Гаусса или медианные фильтры.
- Размер шрифта: Убедитесь, что размеры шрифта в обучающем наборе данных согласуются с реальными образцами. При слишком маленьком шрифте может возникнуть потеря информации о формировании символов.
- Разнообразие данных: Включите разные образцы рукописного текста, включая различные стили написания, чтобы улучшить общую адаптацию модели к сложным случаям распознавания.
- Параметры модели: Настройки, такие как скорость обучения (learning rate) и количество эпох (epochs), напрямую влияют на качество обучения. Проведите тестирование с различными значениями для выбора оптимальных.
- Сегментация символов: Точное разделение символов помогает избежать их смешивания. Используйте морфологические операции или методы машинного обучения для улучшения сегментации.
- Подбор метрик: Используйте метрики, такие как точность (accuracy), полнота (recall) и F1-меру, чтобы оценить качество модели в процессе настройки.
Регулярное тестирование и корректировка параметров обеспечивают стабильное увеличение точности. Следуйте указанным рекомендациям, чтобы добиться максимального результата в распознавании рукописного текста. Сравнивайте коэффициенты точности после каждой настройки для анализа эффективности изменений.
Интеграция модели с пользовательскими приложениями
Начните с выбора подходящего фреймворка для создания вашего приложения. Flask и Django отлично подходят для веб-приложений, тогда как Tkinter или PyQt подойдут для настольных приложений.
После этого настройте сервер для работы с вашей моделью. Например, в Flask вы можете создать API, которое принимает изображение, обрабатывает его через модель распознавания текста и возвращает результат:
from flask import Flask, request, jsonify
import your_model # Импортируйте вашу модель
app = Flask(__name__)
@app.route('/recognize', methods=['POST'])
def recognize():
image_file = request.files['image']
text = your_model.recognize_text(image_file) # Обработка текста
return jsonify({'recognized_text': text})
if __name__ == '__main__':
app.run()
Обратите внимание на обработку ошибок. Убедитесь, что ваш API возвращает корректные статусы и сообщения при ошибках, таких как неверные форматы файлов или сбои в работе модели.
Теперь обеспечьте фронтенд вашего приложения. Если это веб-приложение, используйте HTML и JavaScript для взаимодействия с вашим API. Пример вызова API через Fetch API:
fetch('/recognize', {
method: 'POST',
body: formData
})
.then(response => response.json())
.then(data => {
console.log(data.recognized_text);
});
Для настольного приложения подключите функции модели к интерфейсу, используя кнопки и поля для ввода. Например, создайте кнопку «Распознать», которая отправляет изображение и отображает результат на экране.
Тем не менее, не забудьте проверить производительность вашего приложения. Если оно будет использоваться активно, рассмотрите методы кэширования, чтобы ускорить время отклика.
Не забывайте тестировать приложение с различными образцами рукописного текста для выявления слабых мест модели. Это поможет улучшить её точность и адаптировать интерфейс под реальные сценарии использования.
Заключительный шаг – развертывание приложения. Убедитесь, что сервер настроен на хостинг вашего API. Используйте облачные платформы как Heroku или AWS, чтобы обеспечить доступность вашего сервиса.
Такая интеграция обеспечит пользователям простой способ взаимодействия с моделью распознавания текста прямо в их приложениях.
Тестирование и оптимизация моделей на реальных примерах
При тестировании моделей распознавания рукописного текста используйте реальные образцы данных для проверки точности. Соберите набор изображений с разнообразными почерками, включая различные стили и форматы. Это позволит проверить устойчивость модели к различным условиям.
Применяйте метод кросс-валидации, деля данные на несколько частей. Например, используйте 80% данных для обучения и 20% для тестирования. Это даст возможность оценить производительность модели более объективно. Анализируйте метрики, такие как точность, полнота и F1-мера, чтобы получить полное представление о ее характеристиках.
Оптимизация модели включает в себя настройку гиперпараметров. Исследуйте влияние таких параметров, как скорость обучения и размер батча. Используйте библиотеку Optuna для автоматизации процесса подбора гиперпараметров, что упростит задачу значительным образом.
Не забывайте о предварительной обработке изображений. Использование методов увеличения данных, таких как поворот, обрезка и масштабирование, улучшает обобщающую способность модели. Это позволяет достичь лучшей производительности на новых, не виденных раньше данных.
Для улучшения качества распознавания применяйте ансамблевые методы. Объединение нескольких моделей позволяет снизить вероятность ошибок и повысить надежность. Рассмотрите варианты использования методов голосования или стекинга. Сравните производительность ансамбля с отдельно взятыми моделями, чтобы оценить эффект.
Регулярно обновляйте обучающие наборы. С течением времени почерк может меняться, поэтому актуальные данные повысит точность распознавания. Создайте систему сбора данных от пользователей для постоянного улучшения модели.
Завершите тестирование проверкой на реальных устройствах, таких как планшеты или сканеры. Это поможет оценить, как модель справляется с различными уровнями качества входного изображения и настоящими условиями использования. Анализируйте результаты и вносите изменения в модель, основываясь на полученных данных.